| id_answer | r_it | P | n |
|---|---|---|---|
| iqa | 0.41 | 0.68 | 314 |
| mad | 0.37 | 0.31 | 186 |
| med | 0.41 | 0.85 | 281 |
| mw | 0.30 | 0.72 | 199 |
| q_high | 0.47 | 0.78 | 198 |
| q_low | 0.60 | 0.70 | 117 |
| range | 0.31 | 0.86 | 224 |
| sd | 0.50 | 0.37 | 215 |
| var | 0.52 | 0.37 | 156 |
Bei dieser Aufgabe geht es um die Berechnung von typischen Lage- und Streuungsmaßen. Echte Daten aus einer Studie zur Köperwahrnehmung kommen zum Einsatz. Man lernt sogar noch etwas inhaltliches: Es gibt bestimmte systematische Muster bei Angaben zur Körpergröße und dem Körpgergewicht.
Eine Zufallsvariante der Aufgabe mit allen Fragen sieht wie folgt aus:
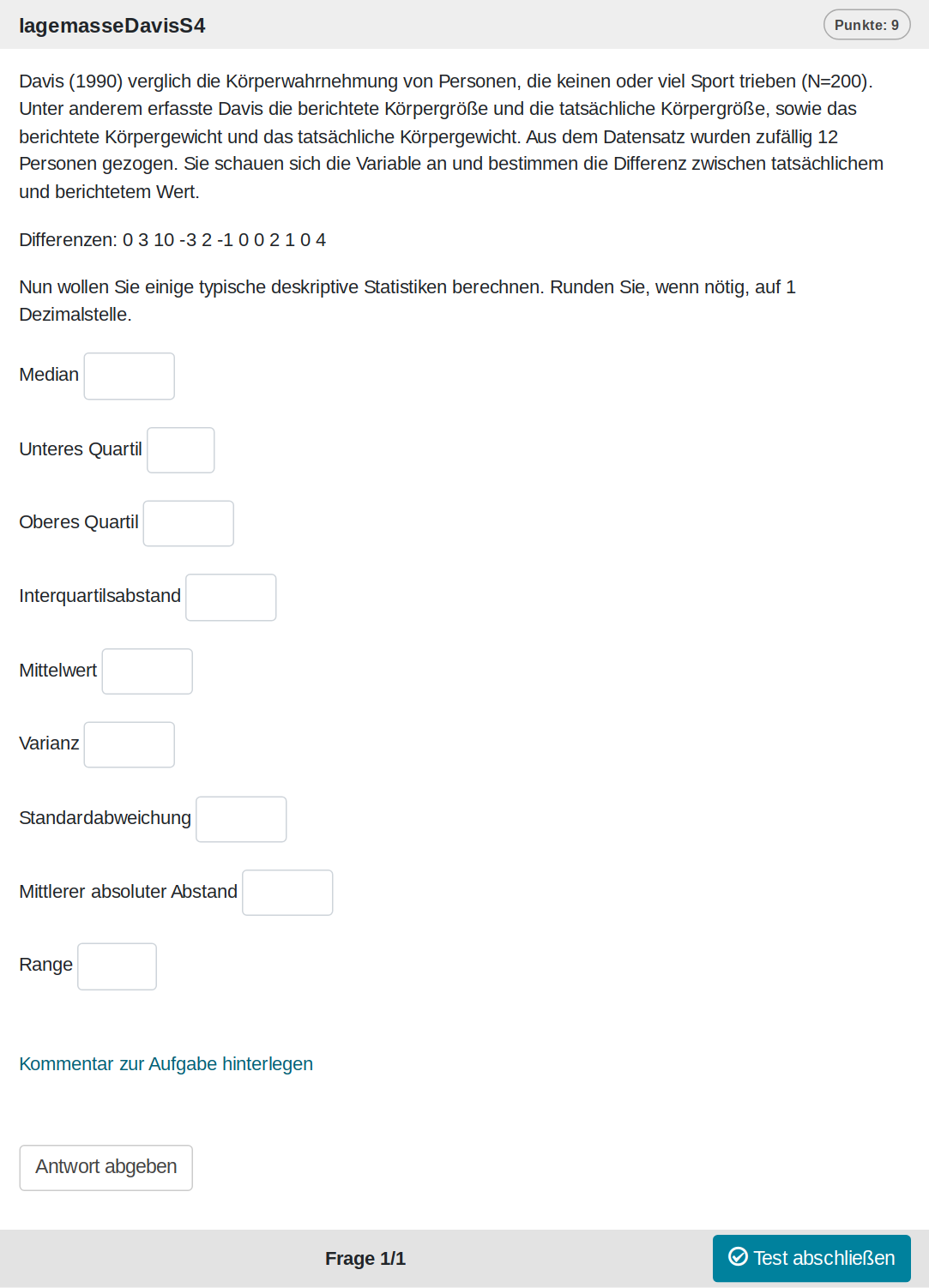
Und kann auf Opal auch direkt ausprobiert werden: Link
Für diese Aufgabe werden alle Berechnungen im Feedback angezeigt. Bei Bedarf können weitere Details mit Studierenden in Übungen besprochen werden.
Die Aufgabe ist natürlich auch Bestandteil des Übungskurses: https://bildungsportal.sachsen.de/opal/auth/RepositoryEntry/38156107780/CourseNode/1691029715285521006
In diesem Fall jedoch mit Modfikationen. Es gibt zwei Sektionen: Sektion A enthält 3 zufällig ausgewählte einfache Berechnungen, Sektion B enthält 2 zufällig ausgewählte schwierige Berechnungen. Da 9 Fragen enthalten sind, wäre die Aufgabe sonst zu lang. So werden nur 5 Fragen gestellt und man kann gut zwischendurch pausieren.
Validierung
Die Aufgabe benutzen wir in der Basisform schon relativ lange, weshalb sowohl im Übungskurs als auch in Klausuren viele Antworten entstanden sind. Zunächst aus dem Übungskurs:
Die Trennschärfen (r_it) sehen durchweg gut aus. Auffällig sind die Quartile (q_high und q_low), die besonders trennscharf sind. Nach unseren Erfahrungen ist dies zu erwarten, denn viele Studierende berechnen Quartile intuitiv, anstatt sich auf Formeln zu stützen. Dies kann schnell zu Fehlern führen. Natürlich gibt es verschiedene Möglichkeiten Quartile zu berechnen; man kann also oft nicht wirklich sagen, dass eine ähnliche Lösung komplett falsch wäre. Hier geht es meiner Meinung nach eher darum die formale Arbeit zu üben; Formeln zu kennen und richtig anzuwenden.
Die Schwierigkeiten (P) schwanken deutlich zwischen den Items. Dies könnte man bei Klausuren berücksichtigen um sie etwas leichter oder schwerer zu machen.
Zu beachten ist, dass Studierende im Übungskurs eine Zufallsauswahl von Items bekamen. Die diagnostischen Kriterien sind also in diesem Kontext zu bewerten. Eine bestimmte Konstellation der Items könnte die Werte deutlich verändern. Trotzdem scheint die Aufgabe insgesamt sehr gut zu funktionieren.
Die Bearbeitung der Aufgabe liegt im Schnitt bei 281s.
Nun zu den Klausuren:
| year | GROUP | r_it | P | dur | n |
|---|---|---|---|---|---|
| 2021 | 1 | 0.41 | 0.75 | 344.44 | 36 |
| 2021 | 2 | 0.52 | 0.79 | 303.52 | 21 |
| 2021 | 3 | 0.27 | 0.72 | 363.49 | 37 |
| 2021 | 4 | 0.51 | 0.88 | 253.07 | 28 |
| 2022 | 1 | 0.53 | 0.83 | 329.91 | 23 |
| 2022 | 2 | 0.32 | 0.93 | 340.91 | 35 |
| 2022 | 3 | 0.33 | 0.81 | 403.69 | 29 |
| 2022 | 4 | 0.71 | 0.90 | 373.19 | 26 |
| 2023 | 1 | 0.49 | 0.82 | 511.29 | 42 |
| 2023 | 2 | 0.73 | 0.79 | 448.37 | 27 |
| 2023 | 3 | 0.29 | 0.94 | 399.06 | 31 |
| 2023 | 4 | 0.36 | 0.92 | 354.70 | 33 |
| 2024 | 1 | 0.47 | 0.84 | 652.37 | 102 |
Jede Zeile stellt eine Variante der Aufgabe dar (dur = duration, Dauer der Bearbeitung in Sekunden). 2024 haben wir nur eine Variante verwendet. Insgesamt sind die Trennschärfen gut bis sehr gut. Die Trennschärfe ist im vierten Jahr immer noch bei 0.47. Obwohl also klar ist, dass wir Fragen zu deskriptiven Statistiken stellen, differenziert die Aufgabe trotzdem sehr gut. Wir können sie daher uneingeschränkt anderen Kollegen empfehlen. Die korrekte Berechnung von fundamentalen Lage- und Streuungsmaßen ist ein guter Indikator für das Methodenwissen allgemein. Und das selbst, wenn, wie bei uns, eine Formelsammlung in der Klausur erlaubt ist.
Aufgabe in R nutzen
Die Aufgabe ist etwas komplexer strukturiert als andere. Für Klausuren nutzt man am besten die Funktion lagemaße_klausur. In diesem Fall werden zwar zufällig Daten erzeugt, es werden aber stets die gleichen Fragen gestellt. Man kann über den Parameter question auch selbst eine Auswahl der Fragen vornehmen. Möglich sind:
| Variable | Statistik |
|---|---|
| med | Median |
| q_25 | Unteres Quartil |
| q_75 | Oberes Quartil |
| IQA | Interquartilsabstand |
| mw | Mittelwert |
| var | Varianz |
| s | Standardabweichung |
| MAD | Mittlerer absoluter Abstand |
| R | Range |
Wir verzichten darauf und lassen das Paket die Fragen auswählen. Trotzdem geben wir seeds an um zufällige Daten zu erzeugen:
aufgabe <- methodenlehre::lagemaße_klausur(1:20)Diese könnte jetzt z. B. in eine Sektion gepackt werden, aus der man eine Variante zufällig zieht:
sektion <- section(aufgabe, selection = 1)Und der finale Test:
# ß darf im identifier nicht verwendet werden
test <- test(identifier = "lage", content = sektion)Weitere Details zur Aufgabenerzeugung kann man entsprechend im methodenlehre-Paket nachlesen. Die Auswahl der Fragen lässt sich beipielsweise leicht festlegen (Parameter question). Man kann auch komfortabel eine eigene Version der Aufgabe erstellen über die Funktion lagemaße.
QTI zum Download
Den Test, den wir oben erzeugt haben, können wir nun auch als QTI-Datei schreiben:
createQtiTest(test, ".", verification = TRUE, zip_only = T)[1] "./lage.zip"Über verification wissen wir, dass es eine valide QTI-Datei ist. Und mit zip_only bekommen wir nur die gezippte Datei.
Diese Datei kann man jetzt in Learning-Management-Systeme, die QTI 2.1 unterstützen, importieren. Unter Opal wäre es dann auch möglich diesen Test in andere Tests zu inkludieren. Beispielsweise wenn man als Dozent schon eine Klausur erstellt hat und diese um unsere Aufgabe erweitern möchte.
Wenn die Aufgabe über mehrere Jahre hinweg verwendet werden soll, bietet es sich an für jedes Jahr eine neue Variante zu erstellen.