| id_answer | r_it | P | n |
|---|---|---|---|
| response_1 | 0.30 | 0.64 | 1012 |
| response_2 | 0.24 | 0.89 | 1012 |
| response_3 | 0.25 | 0.91 | 1012 |
| response_4 | 0.30 | 0.60 | 1012 |
Bei dieser Aufgabe geht es um die Interpretation eines t-Tests. Die Aufgabe basiert auf echten Daten und es gibt verschiedene Hypothesen, sodass sie recht komplex ist.
Eine Zufallsvariante der Aufgabe sieht wie folgt aus:
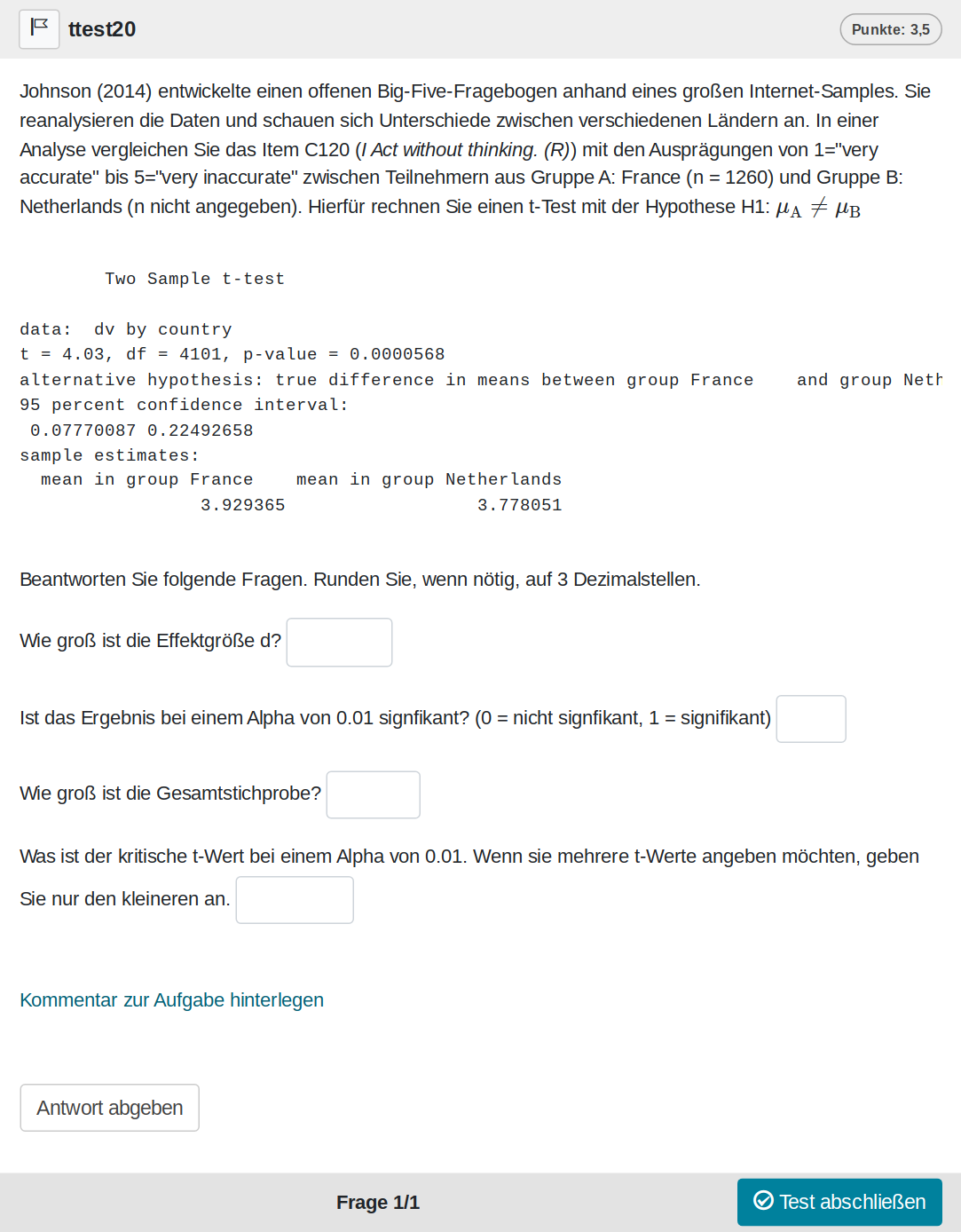
Und kann auf Opal auch direkt ausprobiert werden: Link
Für diese Aufgabe werden alle Berechnungen im Feedback angezeigt. Bei Bedarf können weitere Details mit Studierenden in Übungen besprochen werden.
Die Aufgabe ist natürlich auch Bestandteil des Übungskurses: https://bildungsportal.sachsen.de/opal/auth/RepositoryEntry/38156107780/CourseNode/1675395164331021009
In diesem Fall ohne Modifikationen.
Validierung
Die Aufgabe ist schon recht lange in unserem Kanon, daher haben wir im Übungskurs einige Daten sammeln können. In einer Klausur kam die Aufgabe bisher nur ein Mal zum Einsatz. Zunächst die Übungsaufgaben (r_it ist die Trennschärfe, P die Itemschwierigkeit):
Die Bearbeitung der Aufgabe liegt bei 300s.
Die Trennschärfen sehen leider nicht besonders gut aus. Das heißt aber nur, dass die Aufgaben eher lose zusammenhängen. Die Skills, die man benötigt, scheinen nicht homogen zu sein. Frage 1 (Berechnung von d) und Frage 4 (kritischen t-Wert angeben) sind recht schwer, wohingegen die Bestimmung, ob das Ergebnis statistisch signifikant ist (Frage 2) und die Berechnung der Gesamtstichprobe (Frage 3) keine Probleme macht.
In der Klausur sieht es wie folgt aus:
| year | GROUP | r_it | P | dur | n |
|---|---|---|---|---|---|
| 2023 | 1 | 0.71 | 0.68 | 837.88 | 42 |
| 2023 | 2 | 0.81 | 0.71 | 922.93 | 27 |
| 2023 | 3 | 0.65 | 0.74 | 986.35 | 31 |
| 2023 | 4 | 0.58 | 0.67 | 805.00 | 33 |
Die Trennschärfe ist auszgezeichnet in allen 4 Versionen. Es ist sogar eine der trennschärfsten Aufgaben, die wir haben. Obwohl also die Fragen selbst nicht so gut die Gesamtpunkte der Aufgabe vorhersagen, sagen die Gesamtpunkte der Aufgabe hervorragend das Klausurergebnis vorher. Daraus können wir momentan nur schlussfolgern, dass es wenig Sinn ergibt in Aufgabenbereichen zu denken. Es gibt verschiedene Dinge, die man beim t-Test wissen muss. Diese Dinge lassen sich nicht pauschal als einen einzigen t-Test-Skill definieren. Gleichzeitig scheinen diese verschiedenen Dinge ein Indikator für das Methodenwissen generell zu sein.
Aufgabe in R nutzen
Da sich die Hypothesen bei der Aufgabe zufällig ändern, kann es sinnvoll sein nur eine Version in einer Prüfung zu verwenden. Zur Illustration erstellen wir hier trotzdem 20 Versionen der Aufgabe:
library(methodenlehre)
aufgaben <- ttest(1:20)Diese könnten jetzt z. B. in eine Sektion gepackt werden, aus der man eine Variante zufällig zieht:
sektion <- section(aufgaben, selection = 1)Und der finale Test:
test <- test(identifier = "ttest", content = sektion)Weitere Details zur Aufgabenerzeugung kann man entsprechend im methodenlehre-Paket nachlesen. So ist z. B. die Auswahl der Fragen und der Studie für die Datenerzeugung möglich.
QTI zum Download
Den Test, den wir oben erzeugt haben, können wir nun auch als QTI-Datei schreiben:
createQtiTest(test, ".", verification = TRUE, zip_only = T)[1] "./ttest.zip"Über verification wissen wir, dass es eine valide QTI-Datei ist. Und mit zip_only bekommen wir nur die gezippte Datei.
Diese Datei kann man jetzt in Learning-Management-Systeme, die QTI 2.1 unterstützen, importieren. Unter Opal wäre es dann auch möglich diesen Test in andere Tests zu inkludieren. Beispielsweise wenn man als Dozent schon eine Klausur erstellt hat und diese um unsere Aufgabe erweitern möchte.