| id_answer | r_it | P | n |
|---|---|---|---|
| eta2p | 0.34 | 0.79 | 408 |
| eta2person | 0.52 | 0.73 | 408 |
| fcrit | 0.36 | 0.85 | 408 |
| fvalue | 0.49 | 0.83 | 408 |
| ngroups | 0.31 | 0.94 | 408 |
| nparticip | 0.42 | 0.79 | 408 |
| significant | 0.17 | 0.96 | 382 |
| varpop | 0.49 | 0.88 | 408 |
Bei dieser Aufgabe geht es darum eine ANOVA zu interpretieren. Die Daten sind echt und kommen aus der Sportpsychologie. Da es verschiedene AVs gibt und die Anzahl der Gruppen zufällig gezogen wird, gibt es sehr viele Varianten. Die Aufgabe ist komplex, mit insgesamt 8 Fragen; die zum Teil auch sehr anspruchsvoll sind.
Eine Zufallsvariante der Aufgabe sieht wie folgt aus:
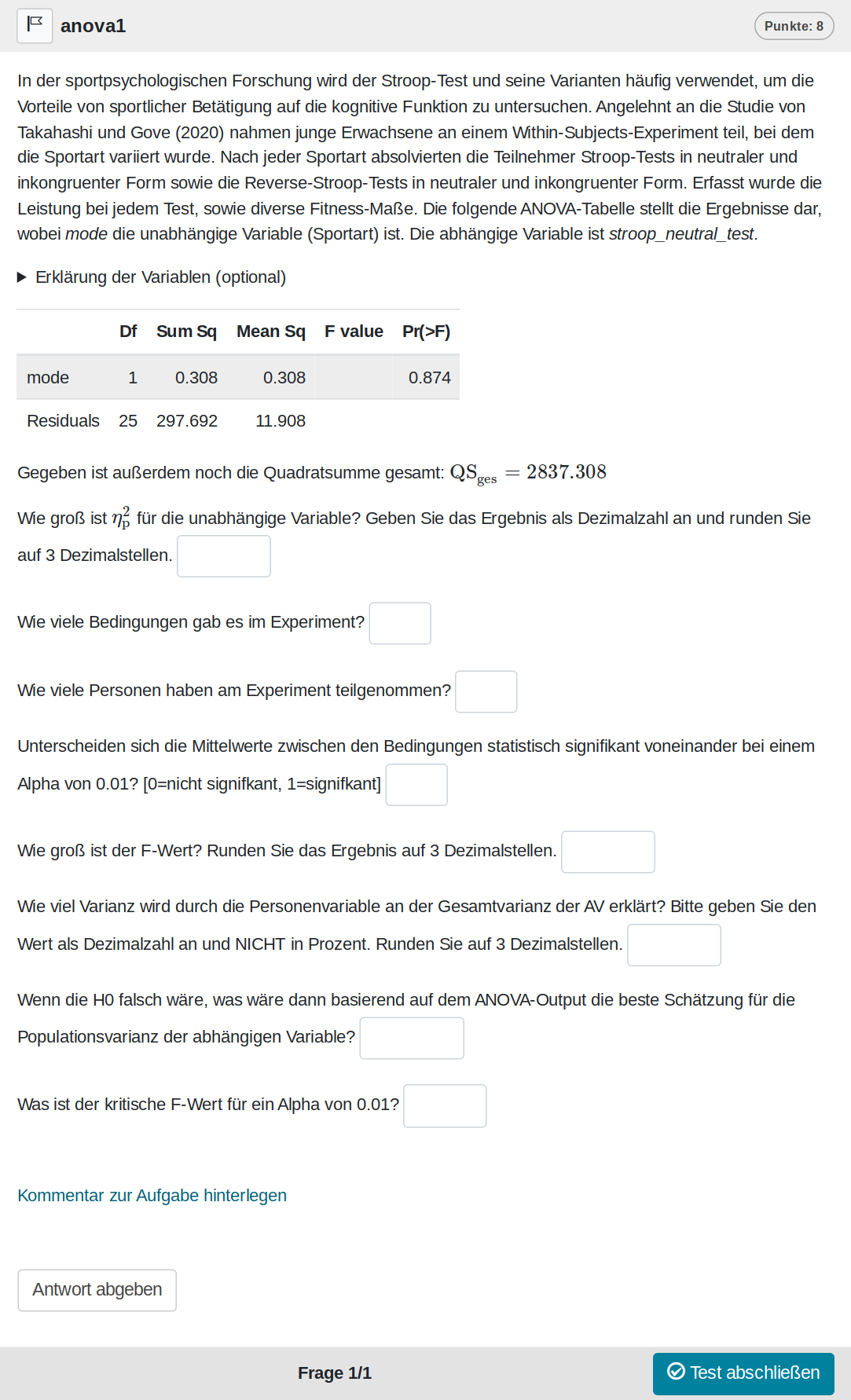
Und kann auf Opal auch direkt ausprobiert werden: Link
Für diese Aufgabe werden alle Lösungen im Feedback angezeigt. Bei Bedarf können weitere Details mit Studierenden in Übungen besprochen werden.
Die Aufgabe ist natürlich auch Bestandteil des Übungskurses: https://bildungsportal.sachsen.de/opal/auth/RepositoryEntry/38156107780/CourseNode/1716777144988148006
In diesem Fall ohne Modifikationen.
Validierung
Zunächst die Validierung zu den Übungsaufgaben (r_it ist die Trennschärfe, P die Itemschwierigkeit):
Die Bearbeitung der Aufgabe liegt bei 489s.
Zu beachten ist, dass die Frage nach der Signifikanz (significant) erst in der zweiten Version hinzukam.
Die Trennschärfen sehr sehr gut aus, bis auf die Frage significant, die zu leicht zu sein scheint. Die restlichen Schwierigkeiten sehen gut aus.
Für die Beurteilung der Aufgabe ist eine Klausur natürlich aussagekräftiger. Die Aufgabe kam bisher nur in der 2024er Klausur zum Einsatz:
| id_question | r_it | P | dur | n |
|---|---|---|---|---|
| anova2024 | 0.47 | 0.88 | 836.32 | 95 |
Die Trennschärfe ist als gut zu beurteilen, aber die Lösungsrate ist vergleichsweise hoch. Schauen wir uns die Aufgabe auf Item-Ebene an:
| id_answer | r_it | P | n |
|---|---|---|---|
| eta2p | 0.44 | 0.76 | 96 |
| eta2person | 0.71 | 0.87 | 96 |
| fcrit | 0.22 | 0.79 | 96 |
| fvalue | 0.50 | 0.93 | 96 |
| ngroups | 0.56 | 0.97 | 96 |
| nparticip | 0.67 | 0.89 | 96 |
| significant | 0.63 | 0.96 | 96 |
Die Frage nach der Signifikanz und der Anzahl der Gruppen wird von fast allen gelöst. Auch die Frage nach dem F-Wert hat eine hohe Lösungsrate. Offensichtlich haben Studierende sich sehr gut auf eine solche Aufgabe vorbereitet. In Zukunft wäre es günstig mehr Fragen zur ANOVA zu konzipieren um eine größere Variation in der Schwierigkeit zu erreichen. Trotzdem sind die Trennschärfen sehr gut, sodass wir die Aufgabe empfehlen können. Inbesondere, wenn Studierende sie in dieser Form noch nicht kennen.
Aufgabe in R nutzen
Wir erstellen 20 Parallelversionen mit den Seeds 1 bis 20:
library(methodenlehre)
aufgaben <- anova(seeds = 1:20)Diese können jetzt in eine Sektion gepackt werden, aus der man eine Aufgabe zufällig zieht:
sektion <- section(aufgaben, selection = 1)Und der finale Test:
test <- test(identifier = "anova", content = sektion)Weitere Details zur Aufgabenerzeugung kann man entsprechend im methodenlehre-Paket nachlesen.
QTI zum Download
Den Test, den wir oben erzeugt haben, können wir nun auch als QTI-Datei schreiben:
createQtiTest(test, ".", zip_only = T)[1] "./anova.zip"Mit zip_only bekommen wir nur die gezippte Datei.
Diese Datei kann man jetzt in Learning-Management-Systeme, die QTI 2.1 unterstützen, importieren. Unter Opal wäre es dann auch möglich diesen Test in andere Tests zu inkludieren. Beispielsweise wenn man als Dozent schon eine Klausur erstellt hat und diese um unsere Aufgabe erweitern möchte.