| id_answer | r_it | P | n |
|---|---|---|---|
| beta | 0.50 | 0.65 | 620 |
| iv_best | 0.33 | 0.92 | 620 |
| yhat | 0.49 | 0.76 | 620 |
Bei dieser Aufgabe geht es um die Interpretation einer multiplen Regression, basierend auf echten Daten aus dem Prestige-Datensatz. Da die einfache Regression sehr ausführlich in der Aufgabe regression abgehandelt wurde, bleiben bei der multiplen Regression nur einige wenige Inhalte übrig.
Eine Zufallsvariante der Aufgabe sieht wie folgt aus:
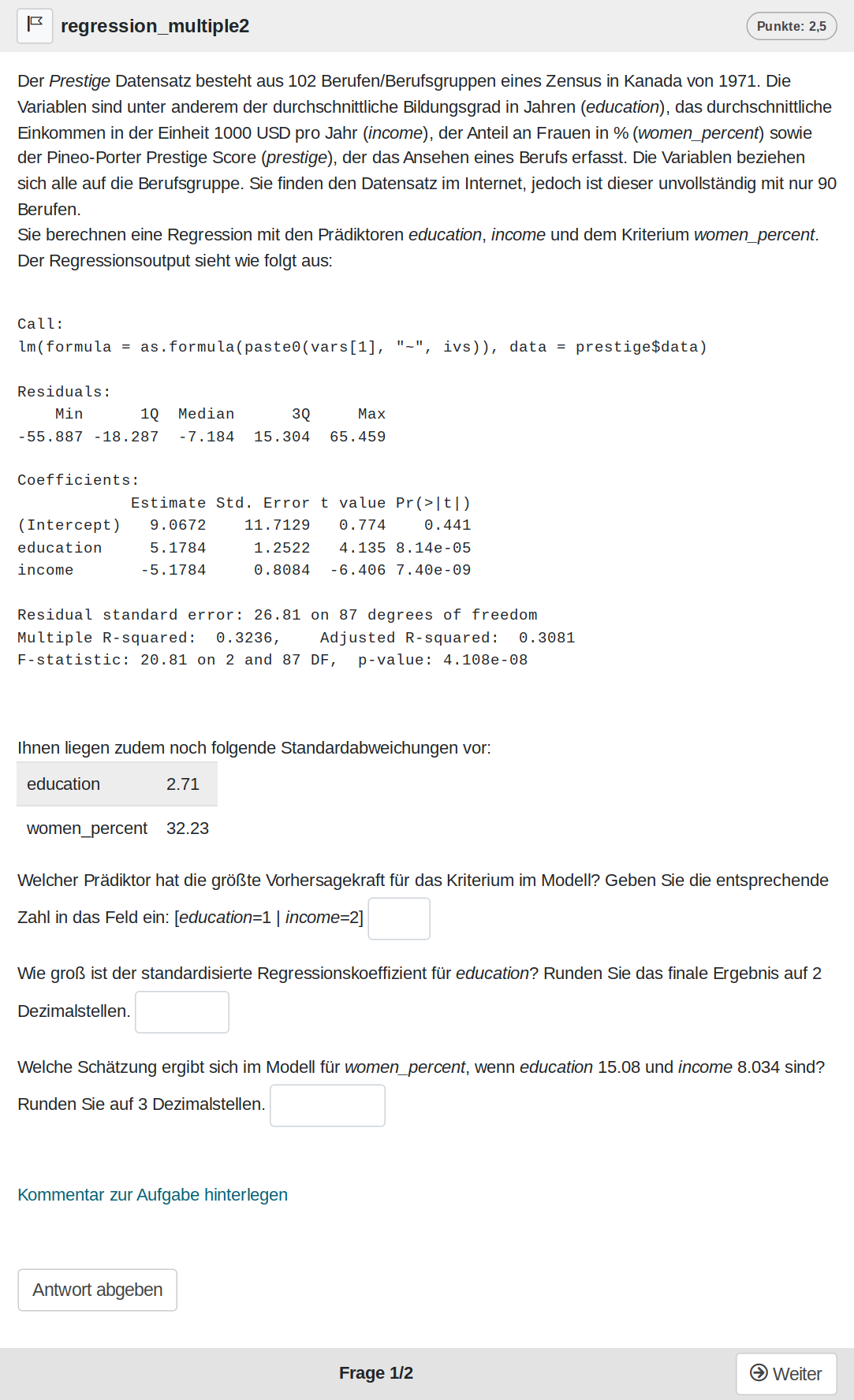
Und kann auf Opal auch direkt ausprobiert werden: Link
Für diese Aufgabe werden alle Lösungen im Feedback angezeigt. Bei Bedarf können weitere Details mit Studierenden in Übungen besprochen werden.
Die Aufgabe ist natürlich auch Bestandteil des Übungskurses: https://bildungsportal.sachsen.de/opal/auth/RepositoryEntry/38156107780/CourseNode/1714617094958510007
In diesem Fall ohne Modifikationen, es werden jedoch 2 Szenarien angezeigt.
Validierung
Schauen wir uns die bisherigen Daten aus dem Übungskurs an (r_it ist die Trennschärfe, P die Itemschwierigkeit):
Die Bearbeitung der Aufgabe liegt bei 235s.
Bisher sehen die Trennschärfen gut aus. Die korrekte Auswahl des besten Prädiktors scheint zu leicht zu sein, was auch zu einer geringeren Trennschärfe führt.
Für die Beurteilung der Aufgabe ist eine Klausur natürlich aussagekräftiger. Die Aufgabe kam bisher nur in der 2024er Klausur zum Einsatz:
| id_question | r_it | P | dur | n |
|---|---|---|---|---|
| regression_multiple2024 | 0.39 | 0.7 | 713.81 | 95 |
Die Trennschärfe ist als gut zu beurteilen, aber die Lösungsrate ist vergleichsweise gering. Schauen wir uns die Aufgabe auf Item-Ebene an:
| id_answer | r_it | P | n |
|---|---|---|---|
| beta | 0.14 | 0.58 | 96 |
| iv_best | 0.16 | 0.94 | 96 |
| yhat | 0.11 | 0.69 | 96 |
Das Problem hängt an der Teilaufgabe beta. Nach Sichtung der konkreten Ergebnisse sind es Rundungsprobleme. Für Beta kam 0.00 heraus, aber viele Studierende haben dies als Lösung nicht akzeptiert und auf 3 Stellen gerundet, obwohl die Aufgabe eine Rundung auf 2 Stellen verlangte. In der aktualisierten Version der Aufgabe gibt es nun eine Warnung, falls bei Beta 0 herauskommt. Die Teilaufgabe beta ist hier also in der Schwierigkeit gebiased und da es nur 3 Teilaufgaben gab, ist auch die Trennschärfe schwer zu beurteilen, insbesondere, da das Item iv_best eine sehr hohe Lösungsrate hat.
Insgesamt gibt es hier also Bedarf nachzusteuern. Man könnte weitere Prädiktoren aufnehmen um die Aufgabe etwas schwerer zu machen. Ggf. wäre es auch möglich eine Frage zu den Residuen zu konzipieren. Berücksichtigt man jedoch die Rundungsprobleme, erscheint die Aufgabe mit der guten Trennschärfe von 0.39 als valide. Tatsächlich steigt die Trennschärfe auf 0.62, wenn man die Rundung auf 3 Stellen als korrekte Lösung akzeptiert.
Aufgabe in R nutzen
Wir erstellen 20 Versionen mit den seeds 1 bis 20:
library(methodenlehre)
aufgaben <- regression_multiple(1:20)Diese können wir in eine Sektion packen, aus der zufällig eine Aufgabe gezogen wird:
sektion <- section(aufgaben, selection = 1)Und der finale Test:
test <- test(identifier = "regression_multiple", content = sektion)Weitere Details zur Aufgabenerzeugung kann man entsprechend im methodenlehre-Paket nachlesen.
QTI zum Download
Den Test, den wir oben erzeugt haben, können wir nun auch als QTI-Datei schreiben:
createQtiTest(test, ".", zip_only = T)[1] "./regression_multiple.zip"Mit zip_only bekommen wir nur die gezippte Datei.
Diese Datei kann man jetzt in Learning-Management-Systeme, die QTI 2.1 unterstützen, importieren. Unter Opal wäre es dann auch möglich diesen Test in andere Tests zu inkludieren. Beispielsweise wenn man als Dozent schon eine Klausur erstellt hat und diese um unsere Aufgabe erweitern möchte.